Este es el cuarto artículo de Mitos de la Inteligencia Artificial, una serie que estudia los fundamentos y conceptos más importantes en inteligencia artificial, machine learning y matemáticas. Puedes encontrar los artículos previos de la colección aquí.
La idea es ofrecer una referencia clara y sencilla que permita comprender, a cualquier lector, el funcionamiento de diversas herramientas que operan a partir del análisis de datos. En la medida de lo posible, se evitará el uso de conceptos grandilocuentes (en la mayoría de los casos no contribuyen a mejorar el entendimiento) y tecnicismos innecesarios pero, si no hay otra alternativa, se ofrecerá una explicación previa con ideas intuitivas y ejemplos.
Si es la primera vez que lees un artículo sobre inteligencia artificial, probablemente sea buena idea revisar antes los textos sobre algoritmos y machine learning, publicados también en esta serie.
Uno de los planteamientos más interesantes sobre el machine learning (ML) es la capacidad que tienen sus algoritmos para identificar patrones y automatizar tareas de una forma más precisa. Esta idea resulta al mismo tiempo atractiva y ambigua. Atractiva porque podemos imaginar a una sofisticada máquina que realiza cálculos y toma decisiones más precisas que un humano, pero apoyada en la evidencia de los datos. Ambigua porque suele provocar una serie de creencias erróneas sobre el funcionamiento de esta rama de la inteligencia artificial. Por ejemplo, ¿cuántas veces nos han tratado de convencer de la eficiencia de un producto únicamente porque éste “aprende solo y va mejorando sus resultados conforme más lo utilizas”? En general, esta clase de afirmaciones vienen acompañadas de una conversación esotérica sobre el funcionamiento del producto, como si explicar el proceso detrás de una herramienta de análisis de datos fuera algo mágico o imposible de entender para los demás.
Si bien una de las principales características de los algoritmos de aprendizaje de máquina es su capacidad de incorporar nuevos datos y, en consecuencia, la posibilidad de mejorar su desempeño a través del aprendizaje, este proceso no tiene porque ser incomprensible ni misterioso. Al contrario, el hecho de que alguien recurra a una explicación esotérica sobre un proceso sustentado en análisis, evidencia y matemáticas (justamente como los algoritmos de ML) podría generarnos dudas sobre el producto o servicio que nos intentan vender, o revelar una falta de entendimiento de aquel que recurre este clase de argumentos o falacias de autoridad para convencernos.
Pero entonces, ¿cómo es que un algoritmo aprende de los datos? ¿Qué algoritmos podemos utilizar? ¿Qué criterios podemos utilizar para la evaluar la precisión de este aprendizaje? ¿Cuáles son los procesos que se deben aplicar a una base de datos antes de utilizarla en alguna herramienta de ML? ¿Cuánto tiempo toma entrenar e implementar esta clase de algoritmos? ¿Cómo podemos utilizar información adicional para que el algoritmo siga aprendiendo? El objetivo de este texto es ofrecer una respuesta clara y sencilla a estas preguntas, con base en la experiencia adquirida por el autor en el ámbito profesional y como profesor de posgrado en temas de análisis de datos e inteligencia artificial.

¿Cuáles son los procesos que se deben aplicar a una base de datos antes de utilizarla en alguna herramienta de ML?
Grosso modo, una de las tareas principales de un científico de datos consiste en utilizar toda la información acumulada sobre un fenómeno o problema, pues se asume que el conocimiento almacenado en estos datos permitirá mejorar el funcionamiento o precisión de alguna tarea. Sin embargo, esta etapa puede ser el inicio de muchos problemas relacionados con la calidad de la información.
En la gran mayoría de los proyectos, los datos a utilizar están desordenados y con una calidad insuficiente para considerarlos como insumo de un algoritmo de machine learning. Además, el proceso necesario para estandarizar y arreglar la información es complejo y generalmente representa la etapa más larga y menos interesante de un proyecto de análisis de datos. Como referencia, en algunas fuentes se estima que un científico de datos invierte el 80 % del tiempo de un proyecto tan sólo en arreglar la información.
Para tener una idea más clara de este tipo de dificultades, pensemos por ejemplo en una base de datos que guarda información sobre los clientes de un banco y además contiene un campo en donde se registra la entidad federativa de cada usuario. ¿Qué pasaría si el nombre del estado de cada cliente se registra de forma manual por distintos empleados del banco? Seguramente los registros no estarían homologados y un mismo estado podría ser escrito de forma distinta, por ejemplo, el estado de Nuevo León podría ser escrito como Nvo. León, N. L., N. León, NL, entre otros.
Además de la falta de homologación de registros, existen otros problemas comunes que enfrenta un científico de datos antes de poder analizar la información:
- Registros incompletos
- Valores nulos o inexistentes
- Distintas escalas
- Campos en mayúsculas y otros en minúsculas
- Faltas de ortografía
- Atípicos y valores extremos
En un nuevo proyecto, el proceso de limpieza y estandarización de datos debería realizarse idealmente una sola vez para arreglar toda información acumulada hasta el momento, mientras que los nuevos datos deberían ser almacenados con los criterios adecuados para poder utilizarlos sin ningún problema. Además existen otras buenas prácticas como el gobierno de datos y los diccionarios de datos que se pueden implementar para asegurar la calidad de la información.
¿Cómo es que un algoritmo aprende de los datos?
Una vez que la base de datos está lista es necesario dividirla en dos conjuntos distintos: entrenamiento y prueba.1 Estos conjuntos tienen funciones distintas y juegan un papel importante en el proceso de aprendizaje.
Conjunto de entrenamiento
- Contiene entre el 70 % y 80 % de los registros.
- Su función principal consiste en proveer datos para probar el desempeño de los distintos algoritmos de aprendizaje de máquina que se desean considerar.
- Gracias a estos datos, se definen una serie de reglas (a través de un algoritmo de aprendizaje de máquina) para predecir el resultado de nuevas observaciones.
Conjunto de prueba
- Agrupa entre el 20 % y 30 % de los registros.
- Se utiliza principalmente para medir el funcionamiento de los distintos modelos que fueron definidos con el conjunto de entrenamiento.
- Con base en la naturaleza del problema (clasificación o regresión), se pueden seleccionar métricas adecuadas para medir el desempeño. Generalmente, se selecciona el mejor modelo para su implementación práctica.
Figura 2: La base de datos original se divide en dos conjuntos: entrenamiento, (para ajustar modelos de ML) y de prueba (para medir el desempeño de los algoritmos).

Generalmente, la separación de registros en entrenamiento y prueba puede realizarse de forma aleatoria, pero si hay una variable temporal en los datos será necesario utilizar otro criterio para evitar un problema de filtración de datos.
En resumen, el conjunto de entrenamiento concentra la mayor parte de los datos y permite que los algoritmos de ML aprendan patrones sobre esta información. Posteriormente, el aprendizaje de cada modelo puede ser evaluado utilizando el conjunto de prueba.
¿Qué algoritmos podemos utilizar?
Los detalles técnicos más importantes de esta pregunta están incluidos en el texto ¿Qué es machine learning? que forma también forma parte de la serie Mitos de la Inteligencia Artificial.
En este artículo me limito a señalar que los algoritmos de ML se pueden dividir en problemas de clasificación o regresión. Además, para cada tipo de problema existen herramientas que pueden considerarse:
- Algoritmos para problemas de clasificación: regresión logística, regresión logística multinomial (para problemas de más de dos clases), árboles de decisión, bosques aleatorios, redes neuronales, entre otros.
- Algoritmos para problemas de regresión lineal: regresión lineal simple, redes neuronales, regresión lineal múltiple, entre otras opciones.
Es necesario considerar que los algoritmos de ML se aplican únicamente al conjunto de entrenamiento. La idea consiste en que estas herramientas identifiquen patrones en estos registros y posteriormente, prueben su desempeño en datos “desconocidos”, contenidos en el conjunto de prueba.
No existe un límite respecto al número de algoritmos que se pueden ajustar al conjunto de entrenamiento. Si bien cada técnica tiene sus propiedades y podría funcionar mejor respecto a distintos tipos de datos, probar distintas opciones permite comparar los resultados de cada una y seleccionar el mejor algoritmo.
¿Qué criterios podemos utilizar para la evaluar la precisión de este aprendizaje?
El desempeño de cada algoritmo se puede evaluar utilizando las métricas disponibles dependiendo de la naturaleza del problema: regresión o clasificación. Para tener una idea intuitiva del funcionamiento de estas métricas, imaginemos el siguiente escenario: trabajas en un hospital y te corresponde evaluar un par de herramientas para detectar de forma temprana si una paciente tiene cáncer de mama. De forma general, estas herramientas analizan cada mamografía para detectar tumores y microcalcificaciones que pudieran ser benignas (no cáncer) o malignas (cáncer). En su aplicación práctica, este tipo de estudios computarizados representan una segunda opinión para un radiólogo y puede ayudar a entregar diagnósticos más precisos.
Desde el punto de vista de ML, el problema es de clasificación ya que existen dos categorías posibles para cada tipo de estudio: cáncer o no cáncer. Para comparar el funcionamiento de las herramientas de predicción, supongamos que la primera utiliza una red neuronal y la segunda una regresión logística, cada una fue ajustada con un conjunto de datos de entrenamiento.
En este tipo de estudios controlados, el hospital ya conoce a qué categoría pertenecen los registros de los conjuntos de entrenamiento y prueba (cáncer o no cáncer). Sin embargo, la idea de probar el desempeño de los algoritmos ajustados con el conjunto de entrenamiento es determinar qué tan bien podría pronosticar la categoría a la que corresponden registros con los que no fue entrenado pues justamente; éste es el escenario que ocurriría en una situación real.
Para comparar los resultados de cada algoritmo, se utilizan 100 registros del conjunto de prueba y se presentan en una matriz de confusión.
Figura 3: Matrices de confusión con los resultados de cada algoritmo. En la diagonal se concentran aquellos registros que fueron clasificados correctamente, independientemente de la clase a la que pertenecen (cáncer o no cáncer). Fuera de la diagonal están los casos clasificados incorrectamente.
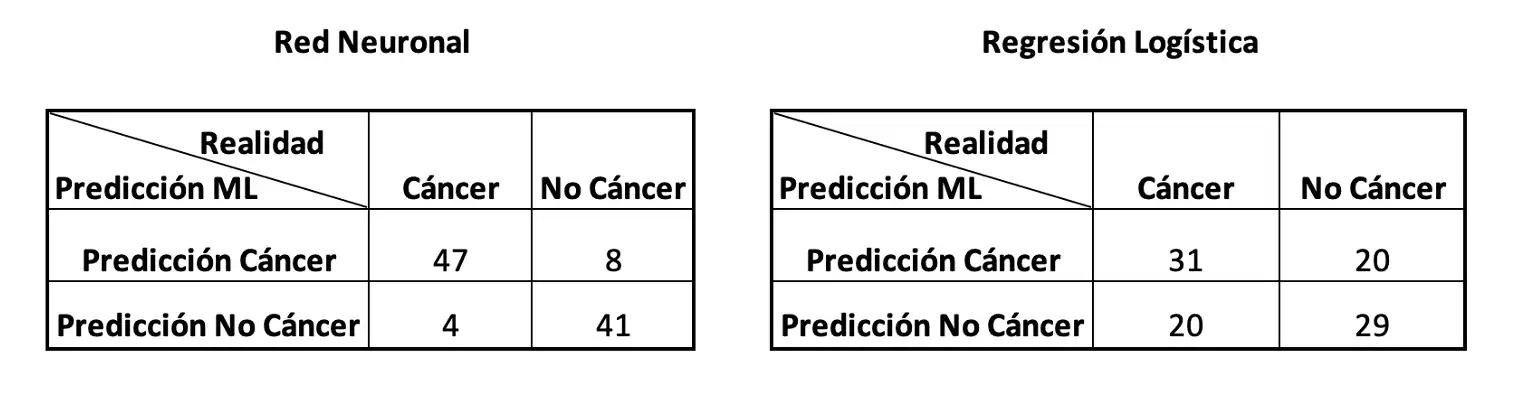
- Al observar los números en la primera fila de la primera matriz de confusión que corresponde a los resultados de la Red Neuronal, se observa que 47 registros de pacientes con cáncer fueron clasificados correctamente, mientras que a 8 pacientes el estudio les dijeron que tenían cáncer pero la predicción es incorrecta.
- Considerando la misma matriz pero el segundo renglón, se observa que el a 4 pacientes les dijeron que no tenían la enfermedad pero en realidad sí tenían cáncer. Por otro lado, las predicciones fueron correctas en 41 pacientes que no tenían cáncer.
- Para tener una idea general de la precisión del algoritmo de la Red Neuronal es posible dividir la suma de los números de la diagonal de la primera matriz entre el número total de casos: 88 / 100 = 0.88. En el argot de ML a este indicador se le llama accuracy e indica el número de registros que fueron pronosticados correctamente por el primer algoritmo, independientemente de su categoría.
- Por otro lado, sumar los números fuera de la diagonal y dividirlo entre el total de casos nos indica el porcentaje de registros con un pronóstico erróneo: 12 / 100 = 0.12 (pacientes con cáncer pronosticados como sin cáncer y viceversa).
- El mismo tipo de métricas puede aplicarse a la segunda matriz de confusión para evaluar el desempeño de su algoritmo de clasificación.
Para ofrecer una explicación más clara, podemos utilizar una notación general que se aplica a las matrices anteriores:
Figura 4: Matriz de confusión y sus componentes para un problema de clasificación de dos clases (mayor referencia aquí)
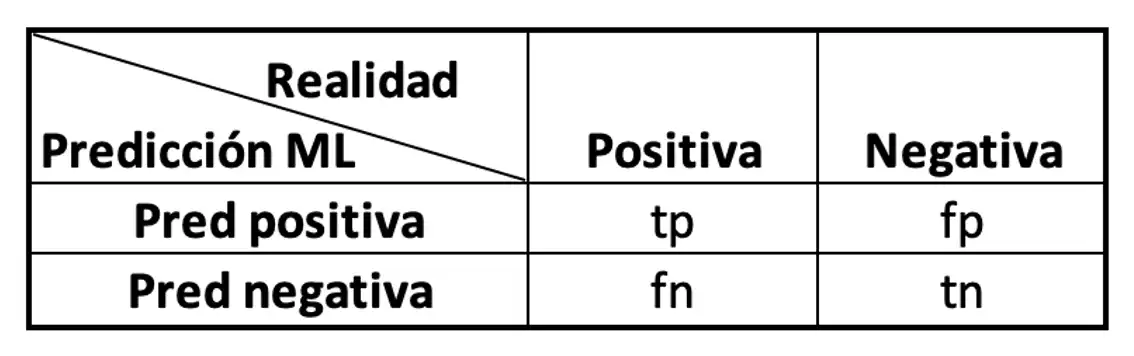
Para analizar los resultados de esta matriz de clasificación, una de las dos clases se debe elegir como positiva, por ejemplo, cáncer lo utilizaremos como positivo y no cáncer como negativo. De esta forma, cada entrada de la matriz de confusión significa:
- tp (true positive): casos positivos que fueron clasificados como positivos, en nuestro ejemplo son los casos clasificados como con cáncer y que en realidad tenían cáncer.
- fp (false positive): casos negativos que fueron clasificados como positivos, es decir, pacientes sin cáncer que les dijeron que sí tenía.
- tn (true negative): casos negativos clasificados como negativos, en nuestro ejemplo significa, pacientes sin cáncer y que les dijeron que no tenían cáncer.
- fn (false negative): casos negativos clasificados como positivos, es decir, pacientes que sí tenían cáncer pero les informaron que no tenían. Este sería una de los indicadores más delicados por el tipo de aplicación en salud: mide el número de personas con cáncer pero que podrían no recibir un tratamiento oportuno a partir de un diagnóstico impreciso, nos interesaría un algoritmo que, entre otras propiedades, reduzca el número de falsos negativos.
A partir de estos indicadores, se pueden calcular otras métricas que miden aspectos más específicos sobre el funcionamiento de un algoritmo, por ejemplo accuracy, recall, precision, F-score, entre otros. En este artículo no se profundizará sobre estos indicadores pues se puede volver innecesariamente técnico, para mayores referencias aquí.
¿Cómo elegir el mejor algoritmo?
Para esta decisión se puede seleccionar una o varias de las métricas disponibles para evaluar los algoritmos. La selección de métricas depende de la naturaleza del problema y en general, se puede seguir las recomendaciones de un científico de datos experimentado y un experto en el tema de aplicación.
Para nuestro ejemplo, supongamos que nos interesa el algoritmo que mejor clasifique la clase correcta (casos con cáncer como cáncer y caso sin cáncer como no cáncer), en este caso podríamos observar que el primer método tiene un accuracy de 0.88 y el segundo de 0.60. Por lo tanto, podríamos seleccionar el primer algoritmo que utiliza una red neuronal.
Figura 3: Todos los algoritmos de ML considerados deben ser evaluados con el mismo conjunto de métricas. El modelo con mejor desempeño es seleccionado.

Posteriormente, el desempeño del modelo seleccionado puede ser evaluado utilizando el conjunto de prueba. En este sentido, se espera que el desempeño que obtenga contra estos registros sea muy cercano al que tendría con datos reales pues, al igual que los datos del conjunto de prueba, estos son desconocidos para el modelo ajustado con los datos de entrenamiento. En general, el desempeño en el conjunto de prueba tiende a ser menor que con el de entrenamiento (en el argot de ML esto se dice como “el error de prueba es mayor que el error de entrenamiento”).
Figura 4: El mejor modelo puede ser evaluado contra los datos del conjunto de prueba para estimar el desempeño real que tendría el algoritmo.

En la mayoría de los problemas de clasificación el accuracy es una de las métricas que más se utilizan, sin embargo, no siempre es tan directo. Considerando el mismo ejemplo de las pacientes con diagnóstico de cáncer, pensemos ahora en la métrica fn (falsos negativos) de ambas matrices de confusión, que mide el número de pacientes que sí tenían cáncer pero que el pronóstico indicó que no tenían la enfermedad. Las implicaciones médicas de un pronóstico erróneo como este podrían hacer que un paciente enfermo no reciba el tratamiento adecuado y de forma oportuna porque el pronóstico fue erróneo. Probablemente, en una aplicación para pronosticar enfermedades minimizar el número de falsos negativos sea tan importante como maximizar el accuracy.
Un proceso similar se puede implementar para problemas de ML de regresión, sin embargo, las métricas para evaluar los algoritmos son distintas, por ejemplo, el error cuadrático medio, la R cuadrada, entre otros.
Es necesario mencionar que si un algoritmo llega a la fase de implementación real existen otros criterios que van más allá de la optimización de un algoritmo o métricas y tiene que ver con decisiones de negocio. Por ejemplo, desarrollar la infraestructura y procesos necesarios para implementar machine learning suele ser costoso, no sólo por los insumos que necesita el equipo (hardware y servidores) sino porque un científico de datos, matemático o estadístico experimentado tiene un sueldo alto debido a su capacidad y a la escasez en el mercado laboral (aquí, aquí y aquí la situación en México en 2016 —ahora los sueldos son aún más altos). Otra de las dificultades comunes puede ser la resistencia a la adopción del nuevo algoritmo por parte del área usuaria (que implica que dejen de utilizar el método que antes utilizaban).
De hecho, uno de los ejemplos más icónicos de este tipo de dificultades ocurrió hace varios años cuando Netflix ofreció un millón de dólares a quien pudiera mejorar su algoritmo Cinematch que permitía pronosticar las calificaciones de películas que los usuarios no habían visto y en consecuencia, ofrecerles mejores recomendaciones y conservarlos como suscriptores satisfechos con el servicio recibido. La compañía pagó el premio pero no implementó el modelo porque requería un gran esfuerzo en términos de ingeniería y procesos.
¿Cómo podemos utilizar información adicional para que el algoritmo siga aprendiendo?
De acuerdo al ejemplo presentado sobre los pronósticos en salud, el hospital podría utilizar la red neuronal para dar un pronóstico a sus próximos pacientes, estos nuevos datos permitirán determinar el desempeño real que tiene algoritmo y sobre todo, esta información adicional podría mejorar la precisión y funcionamiento del sistema de pronóstico del hospital.
De hecho, después de un cierto tiempo sería natural suponer que se debe repetir el proceso de separación en entrenamiento-prueba, aprendizaje, algoritmos y métricas con los nuevos registros. Esto podría resultar en la selección de un nuevo algoritmo (que podría no ser la misma red neuronal) que entregue mejores resultados, gracias a que el sistema puede aprender de nuevos datos, detectar nuevos patrones y, por lo tanto, hacer mejores predicciones. A este proceso también se le conoce como recalibración del modelo.
Probablemente, si un producto pudiera autorreplicar todo el proceso descrito en este artículo —desde la limpieza de los datos, análisis de atípicos, la selección de algoritmos, métricas e infraestructura—, podríamos pensar que “un algoritmo aprende solo”. Sin embargo, tan sólo la idea de pensar en un proceso que se encargue de limpiar y estandarizar toda la información que consume un algoritmo, suena complicado y poco factible.
En resumen, se puede observar que, si bien la etapa de entrenamiento y aprendizaje de una herramienta de machine learning implica una serie de procesos técnicos que requieren mucha precisión y estructura, no se trata de algo esotérico en donde una máquina misteriosa empieza a tomar decisiones únicamente porque alguien introduce algunos datos. Aunque las complicaciones técnicas empiezan justamente al estandarizar esta información (además consumen la mayor parte del tiempo de un proyecto de ML) y el proceso se vuelve aún más complejo y técnico al ajustar los algoritmos y decidir el mejor, siempre es posible explicar claramente cómo funciona el proceso de aprendizaje en machine learning.
La desinformación y el uso de discursos sensacionalistas alrededor del funcionamiento de los algoritmos de ML o productos de inteligencia artificial no contribuye al aprovechamiento de uno de una de las mayores ventajas de estas herramientas: resolver problemas complejos y mejorar la toma de decisiones en las múltiples áreas en donde pueden ser utilizados; desde salvar una vida a través de un mejor diagnóstico médico, optimizar una estrategia de seguridad pública o crear mejores productos para el mercado, entre muchas otras aplicaciones.
Carlos Castro Correa
Licenciado en Matemáticas Aplicadas y Maestro en Ciencia de Datos por el Instituto Tecnológico Autónomo de México. Consultor y profesor de Análisis de Datos e Inteligencia Artificial en distintos programas de Maestría del ITAM.
Agradezco a Sebastián Garrido de Sierra y Javier Yaíro Muñoz Fernández de Córdova por sus comentarios y observaciones.
1 Algunos científicos de datos acostumbran dividir las bases de datos en tres conjuntos: entrenamiento, prueba y validación, en este caso el porcentaje de registros sería, por ejemplo, 60 %, 20 % y 10 %, respectivamente; sin embargo, la opción de utilizar únicamente dos conjuntos parece más frecuente.