En México, las elecciones para gobernador siempre se realizan en domingo y los resultados oficiales se presentan a la población unos días después. Con el fin de mitigar posibles vacíos de información y prevenir anuncios de victoria injustificados durante ese período, el INE organiza un conteo rápido el mismo día de la elección. Este ejercicio consiste en seleccionar una muestra aleatoria de las casillas y estimar el porcentaje de votos a favor de cada candidato. Para ello, el INE crea un comité de especialistas encargado de producir las inferencias, las cuales se presentan en intervalos con un nivel de confianza de al menos el 95 %.
En las elecciones del 5 de junio de 2022 se votarán los cargos de gobernador de seis estados del país: Aguascalientes, Durango, Hidalgo, Oaxaca, Quintana Roo y Tamaulipas. Es la primera vez que el INE organiza un conteo rápido en estas seis entidades, señal de la importancia que ha cobrado este ejercicio en los últimos años. La rapidez y precisión del conteo fomentan la confianza en la población y sirven como herramienta contra el fraude.

¿Cómo funciona?
El comité encargado del conteo rápido elige un diseño muestral apropiado para cada estado. Éste dependerá de diversos factores como el número de casillas totales y la heterogeneidad de la población. Con el diseño se selecciona una muestra; posteriormente, el día de la elección, se cierran las casillas a las 6 p.m. y comienza a funcionar el sistema que transmite la información de dicha muestra al comité de especialistas.
Cada cinco minutos los integrantes del comité recibimos nueva información de los resultados de votos en casillas y, conforme avanza el tiempo, se va acumulando el número de casillas con las que realizamos el análisis. Para que el conteo sea relevante, quisiéramos publicar resultados la misma noche de la elección, antes de que la gente se acueste a dormir. Sin embargo, las muestras diseñadas no llegan completas a tiempo para publicar los resultados, por lo tanto, los resultados se anuncian utilizando una parte de dichas muestras.
¿Por qué esto hace del conteo un desafío interesante?
Imaginemos que queremos estimar el promedio que sacará un grupo de alumnos en un exámen. Para hacerlo más rápidamente consideramos únicamente a los alumnos que entregaron su exámen en los primeros 30 minutos. ¿Qué podría resultar mal de esa estimación? Varias ideas surgen inmediatamente. ¿Qué tal que los alumnos entregaron el exámen rápido porque no sabían nada? O, ¿qué tal que lo entregaron rápido porque sabían todo? Los datos con los que estamos estimando el promedio podrían estar sesgados, esto quiere decir que existe cierto grado de asociación entre el hecho de que un examen sea entregado en un momento determinado y la respuesta que pretendemos medir: la calificación.
La analogía puede utilizarse para los datos del conteo. ¿Qué tal que las casillas en zonas urbanas entregan más rápido resultados? O, ¿qué tal que las casillas de toda una parte del país se retrasan por fuertes lluvias? Al utilizar una parte de la muestra, las casillas que aún no llegan no faltan de manera aleatoria. Hay muchos factores que inciden en la hora de llegada de una casilla. Conocer los factores nos ayuda a corregir las estimaciones, pero también hay variables que no podemos tomar en cuenta, pues inciden tanto en la hora de llegada como en las decisiones de voto. Es decir, existe cierto grado de asociación entre el hecho de que una casilla sea reportada en un momento determinado y la respuesta que pretendemos medir: el porcentaje de votos por cada candidato.
Anteriormente, el comité fijaba ciertos criterios que debían cumplirse antes de publicar los resultados. Por ejemplo, tener casillas en la muestra de todos los distritos federales, lo que aseguraba representatividad territorial. También observábamos que las estimaciones fueran estables conforme llegaban más datos. Aun con estos criterios, esperábamos salir con el mayor porcentaje de muestra posible para reducir los riesgos.
¿Cómo acelerar la rapidez de los resultados del conteo rápido?
Para las próximas elecciones, nuestro equipo usará un modelo jerárquico bayesiano que resulta útil en este tipo de escenarios. La idea central es utilizar una regresión para modelar las respuestas de casillas individuales en función de diferentes atributos, incluidos los factores que sabemos que influyen en la hora de llegada. Cuando la información de una casilla falta, atrae los parámetros de la casilla hacia otras casillas con atributos similares a ella. Como consecuencia, obtenemos mejores resultados en caso de que los datos de la submuestra estén sesgados.
Adicionalmente, hacemos un ajuste en función del porcentaje de muestra observado que aumenta el tamaño de los intervalos entre más casillas faltantes hayan. Esto tiene sentido, pues refleja la incertidumbre que tenemos cuando falta más muestra por llegar.
¿Cómo podemos saber que el modelo funciona?
Podemos probar utilizando los resultados de elecciones anteriores, sin embargo, el número de elecciones anteriores es limitado y el que una muestra funcione o no puede deberse a varios factores, incluyendo buena o mala suerte. También podemos considerar todas las casillas de una elección, sacar muchas muestras con el diseño que se utilizó en dicha elección y probar qué tan bien estimamos. En este segundo caso tenemos un conjunto grande de muestras con las que podemos probar. Sin embargo, sabemos que el día de la elección no estimaremos con las muestras completas y las partes que falten no faltarán al azar. Entonces, ¿cómo probamos con partes de las muestras? ¿Cómo sabemos que casillas quitar?
Necesitamos un procedimiento para quitar casillas que se parezca al verdadero proceso en que llegan las casillas el día de la elección. Así, ajustamos un modelo de supervivencia para los tiempos de llegada de las casillas en las elecciones de 2018 y comprobamos su ajuste con varias elecciones estatales de distintos años. Los modelos de supervivencia abordan el problema de modelar las observaciones del tiempo hasta un evento determinado (por ejemplo, supervivencia desde el diagnóstico de una enfermedad hasta la muerte de una persona). En este caso modelamos el tiempo hasta que una casilla se reporta.
Veamos como ejemplo el estado de Quintana Roo. Consideramos todas las casillas de la elección de gobernador de 2016 y obtenemos 150 muestras con el diseño que se utilizó en dicha elección. Utilizando el modelo de supervivencia simulamos tiempos de llegada para cada casilla de cada muestra. Así, podemos cortar el momento en que llegan 50 % de las casillas, 70 % y 90 %, creando escenarios para evaluar qué pasaría si presentaremos resultados con estos cortes. Posteriormente, estimamos intervalos para cada uno de los cortes y cada una de las 150 muestras.
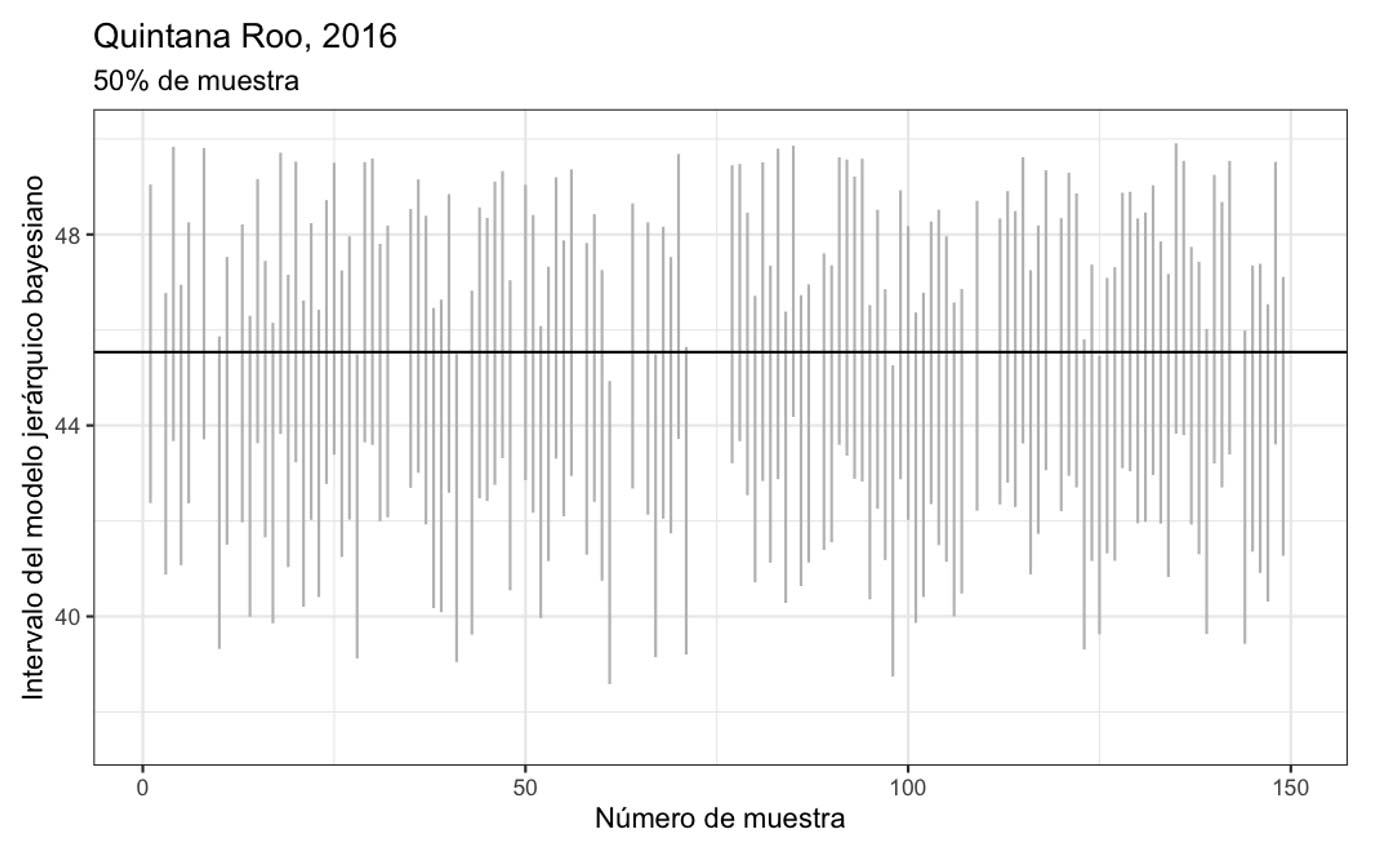
Veamos los intervalos para un candidato cuando han llegado el 50 % de las casillas.
Ahora veamos los intervalos del mismo candidato cuando han llegado el 90 % de las casillas.
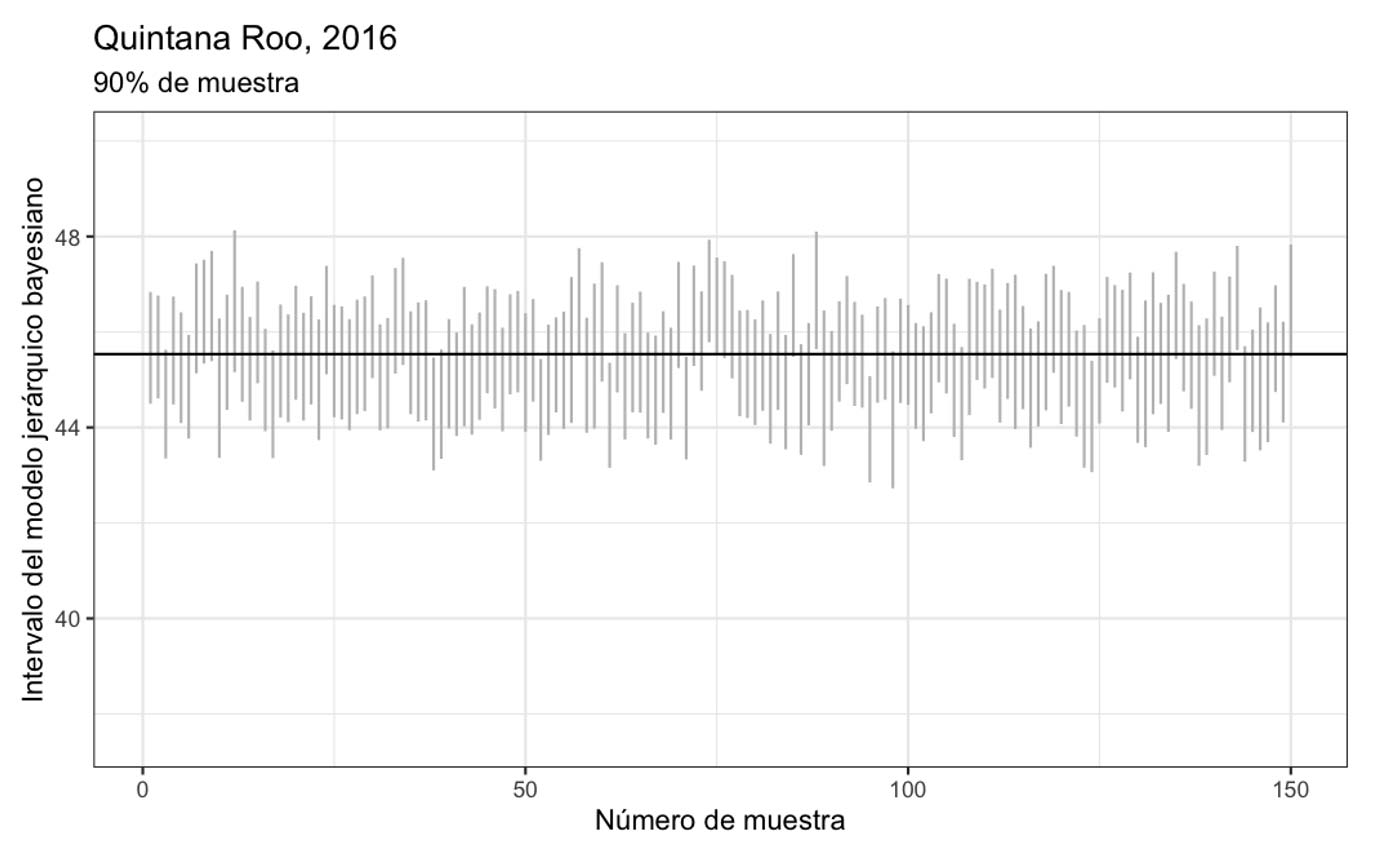
Cuanto mayor es el porcentaje de muestra que falta, mayores son los intervalos. Notemos además que, en ocasiones, el intervalo no contiene el valor real (marcado con la línea negra horizontal). Dado que los intervalos producidos son del 95 % de confianza, lo que esperamos que suceda es que en el 95 % de las muestras, aproximadamente, el valor real esté contenido en el intervalo. En esta ocasión, cuando hay 50 % de la muestra, 144 de las 150 muestras contienen el valor y, cuando hay 90 % de muestra, 140 de las 150 muestras contienen el intervalo.
A continuación aparece una tabla que muestra el porcentaje promedio de veces que el valor real cae en el intervalo, promediando sobre las 150 muestras y sobre todos los candidatos para el estado de Quintana Roo. Como punto comparativo, aparece también en la tabla el estimador de razón combinado, el método estadístico más frecuente para realizar este tipo de análisis.
|
porcentaje de muestra |
50 % |
70 % |
90 % |
|
jerárquico bayesiano |
95 % |
95 % |
93 % |
|
razón combinado |
76 % |
82 % |
93 % |
El modelo jerárquico bayesiano produce intervalos de confianza aproximadamente del 95 % en todos los casos, incluso con ciertos patrones de llegada de casillas observados en elecciones anteriores. Esto reduce el riesgo de presentar resultados con menores porcentajes de muestra.
Un ejemplo con datos reales
Veamos por último una gráfica del modelo utilizando datos de una elección real. A continuación podemos ver cómo fueron evolucionando los intervalos en el estado de Nayarit para los cuatro candidatos con más votos en la elección de gobernador de 2021. La gráfica llega hasta el momento en que publicamos resultados, a las 23:35 con el 65.9 % de la muestra. Las líneas punteadas marcan los porcentajes calculados con la totalidad de las casillas.
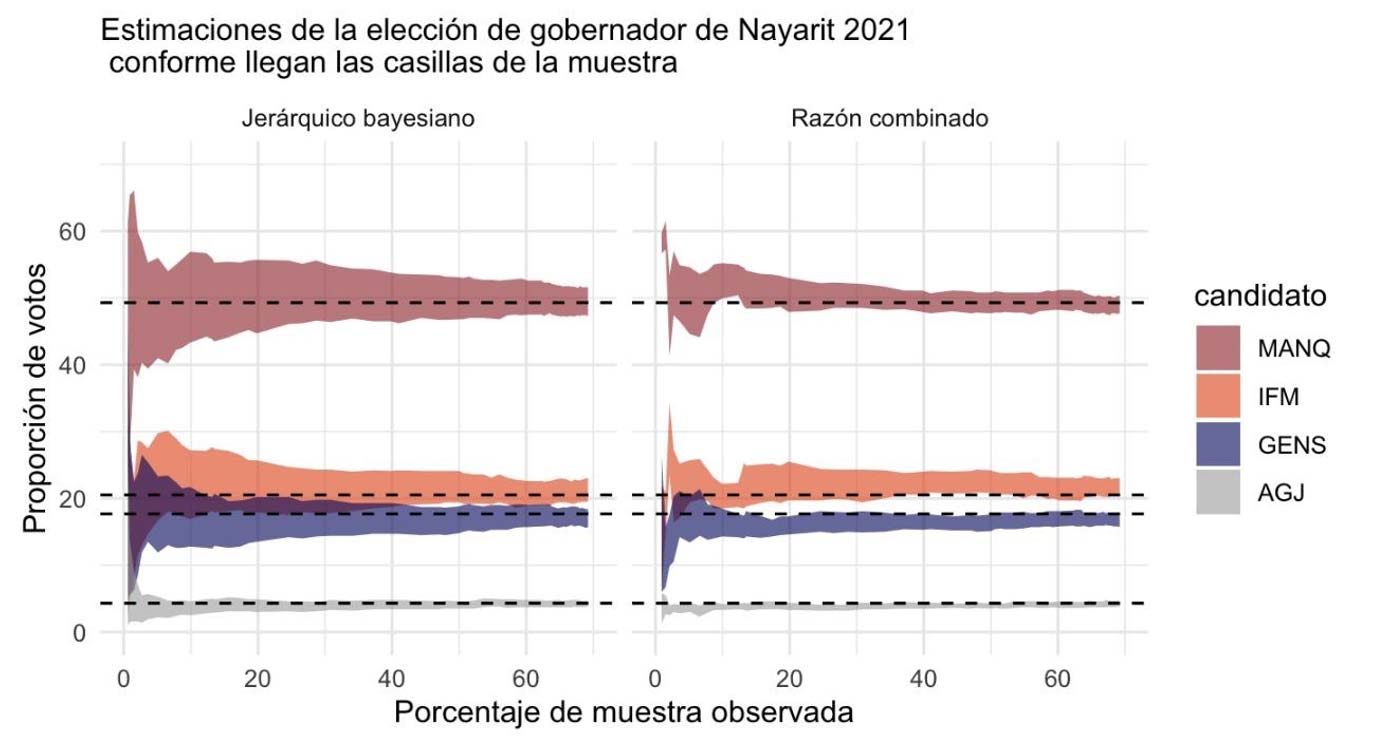
El modelo jerárquico bayesiano aprende rápidamente de los datos, por lo que las trayectorias se estrechan en poco tiempo. La longitud de los intervalos disminuye a medida que llega la muestra, representando la incertidumbre. Además, los intervalos contienen los valores verdaderos todo el tiempo.
Los modelos son representaciones de la realidad y, como tales, nunca serán perfectos. Sin embargo, la iteración y las nuevas herramientas computacionales y estadísticas nos acercan cada vez a mejores resultados. El modelo jerárquico bayesiano, y todos los análisis de los que hablamos en este texto, pueden consultarse a detalle aquí y podrán reproducirse en su totalidad utilizando los datos de las elecciones que se publican de manera abierta en el portal del INE y el paquete de R quickcountmx.
Este es uno de los muchos desafíos que tienen los conteos rápidos. Quedará pendiente para otros textos ahondar en otros retos de estos importantes procesos dentro de las elecciones del país.
Michelle Anzarut
Doctora en estadística aplicada
Luis Felipe González
Doctor en matemáticas, analista de datos
María Teresa Ortiz
Analista de datos con experiencia en ecología e investigación de mercados
El trabajo aquí descrito se realizó por el equipo integrado por Michelle Anzarut, Felipe González y Teresa Ortiz, en el marco de las actividades del Comité Técnico del Conteo Rápido 2022. El comité estuvo conformado por 3 equipos más que aportaron metodologías propias, para conocer más detalle visita aquí.